
We Are Invited to Climb
A book of dynamic chance poetry

The Complete Bach Cello Suites on Melodica
My first album is now available!

The Melodica Drone & Bach Quartet
The world's premier melodica quartet!
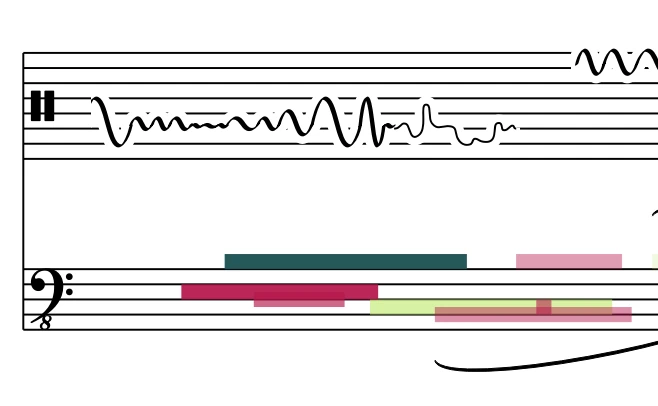
Neoscore
A graphical music notation library
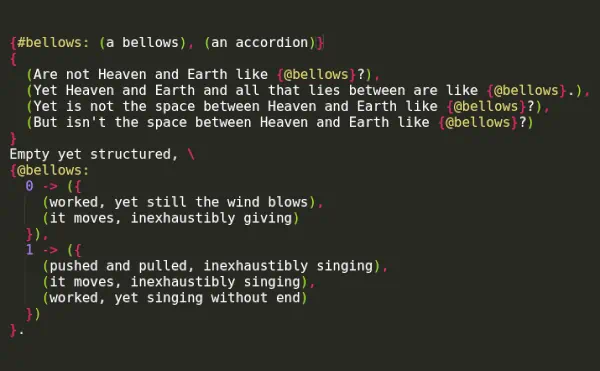
BML
A chance text programming language

The Poetron
A generative poetry installation
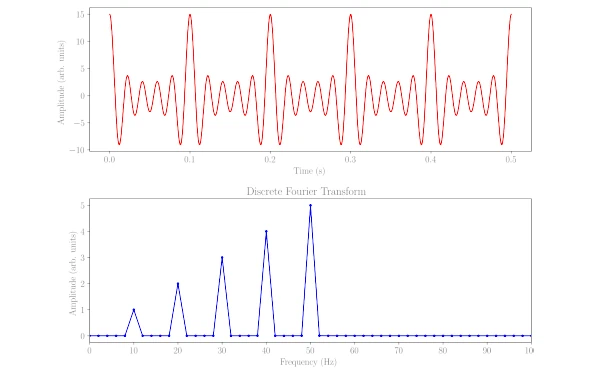
The Rocoder
A live-codeable phase vocoder

A Short While
A sound stretching installation
The best way to keep up with what I'm doing is my mailing list.
upcoming events
more...
recent posts
- Visiting home in Korea (and I'm reading in NYC on Monday!)
- The Complete Bach Cello Suites on Melodica comes out June 3!